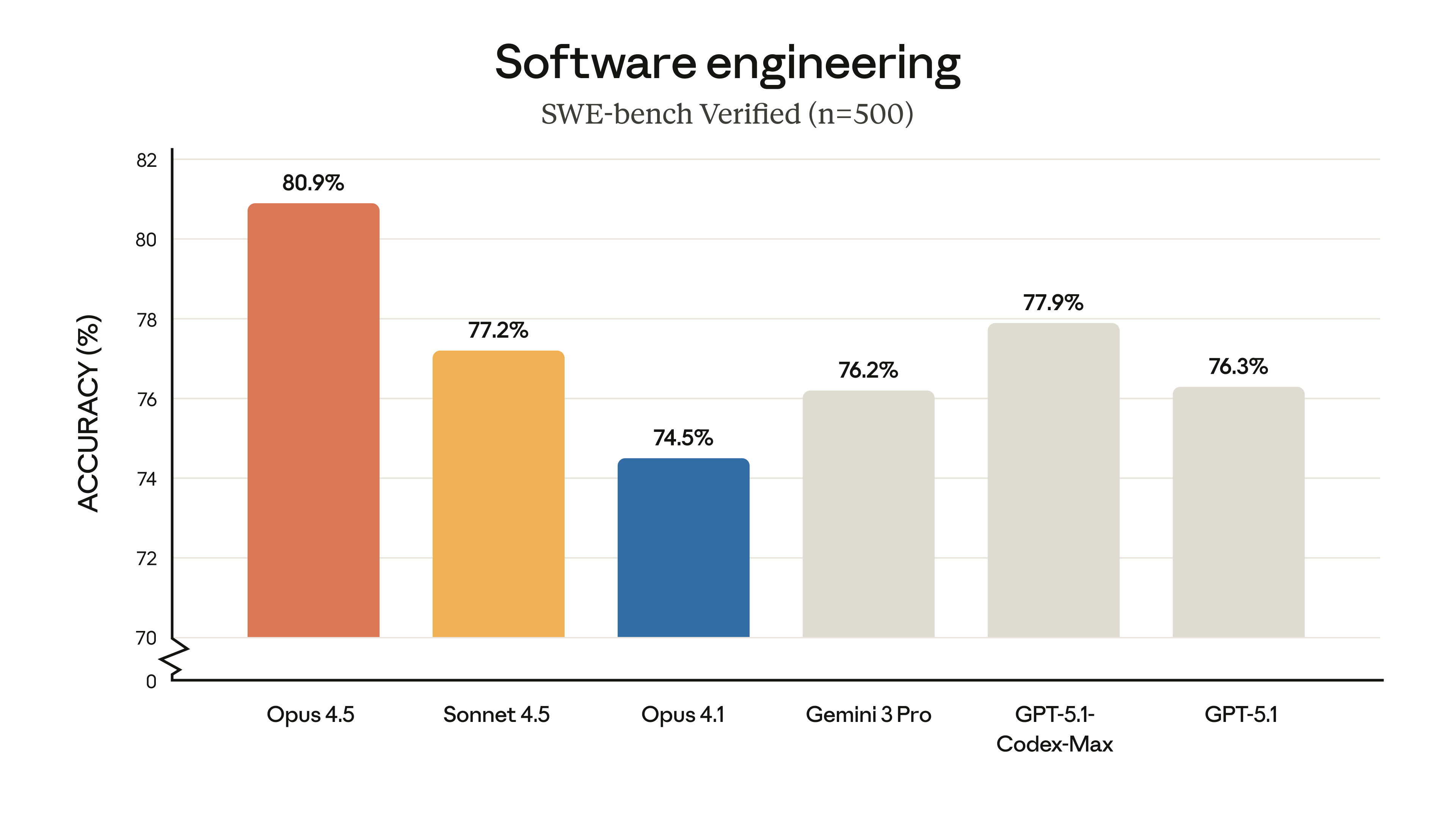
Anthropic just dropped Claude Opus 4.5, and the benchmarks are impressive. With an 80.9% score on SWE-bench Verified—the industry's most rigorous coding benchmark—Opus 4.5 reclaims the coding crown from Google's Gemini 3 Pro while delivering dramatic cost reductions and efficiency improvements.
The Headline Numbers
SWE-bench Verified: 80.9% — This isn't just a marginal improvement. Opus 4.5 outperforms all frontier models including GPT-5.1 (76.3%), GPT-5.1-Codex-Max (77.9%), and Gemini 3 Pro (76.2%) on real-world software engineering tasks.
Pricing: 66% reduction — At $5 per million input tokens and $25 per million output tokens, Opus 4.5 costs dramatically less than its predecessor Opus 4.1 ($15/$75). This makes frontier-level AI accessible to a much broader range of developers and enterprises.
Token Efficiency: Up to 76% fewer tokens — The new effort parameter lets developers balance capability vs. cost. At medium effort, Opus 4.5 matches Sonnet 4.5's best performance while using 76% fewer output tokens.
Comprehensive Benchmark Dominance
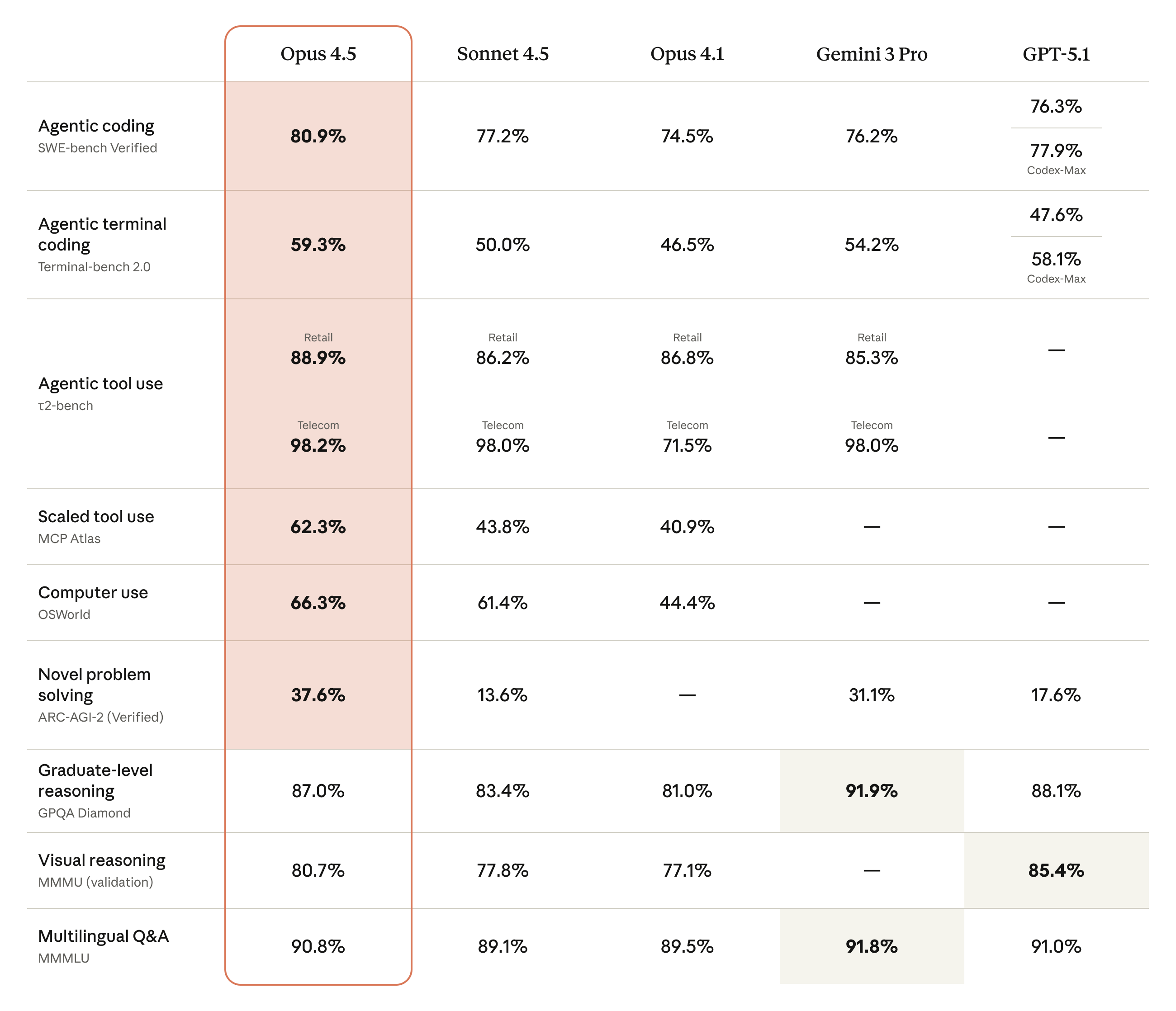
The benchmark table tells the full story. Opus 4.5 leads or ties in nearly every category that matters for developers:
Agentic Capabilities
- SWE-bench Verified: 80.9% (industry-leading)
- Terminal-bench 2.0: 59.3% vs Sonnet 4.5's 50.0%
- OSWorld (Computer Use): 66.3% — the best computer-using model available
- MCP Atlas (Scaled Tool Use): 62.3% vs Sonnet 4.5's 43.8%
- τ2-bench (Agentic Tool Use): 88.9% Retail, 98.2% Telecom
Reasoning and Knowledge
- ARC-AGI-2 (Novel Problem Solving): 37.6% vs GPT-5.1's 17.6%—a 2x advantage
- GPQA Diamond (Graduate Reasoning): 87.0%
- MMMU (Visual Reasoning): 80.7%
- MMMLU (Multilingual Q&A): 90.8%
The Effort Parameter: A Game Changer
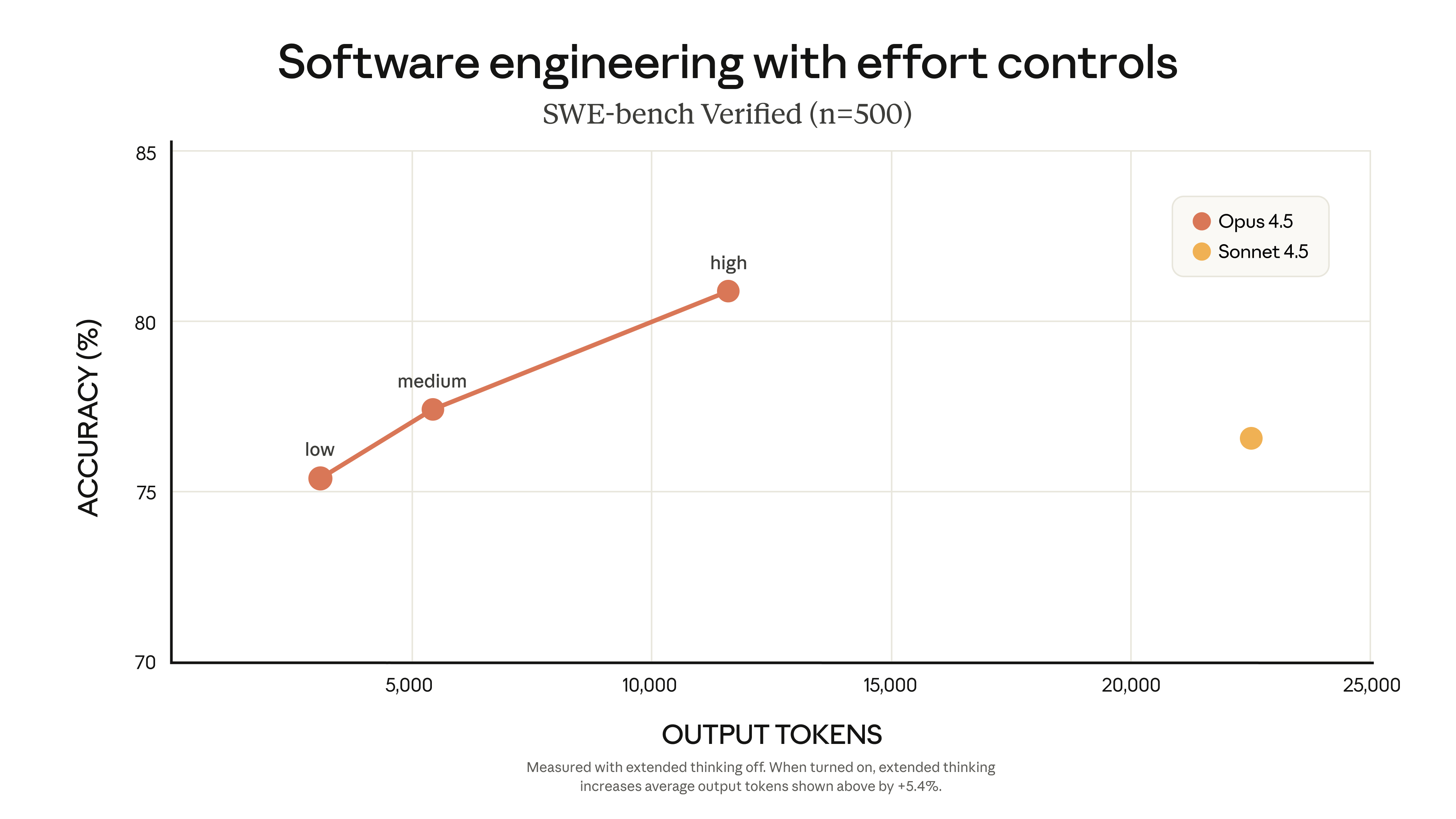
Perhaps the most significant feature for developers is the new "effort" parameter. This API setting (low, medium, high) lets you control how much computational work the model does for each request.
The implications are significant:
- Low effort: Fast responses for simple queries, minimal token usage
- Medium effort: Matches Sonnet 4.5's peak performance with 76% fewer tokens
- High effort: Exceeds Sonnet 4.5 by 4.3 percentage points while still using 48% fewer tokens
This means you can optimize for cost on routine tasks and dial up capability when tackling complex problems—all with the same model.
Multilingual Coding Excellence
Opus 4.5 leads on 7 of 8 programming languages on SWE-bench Multilingual:
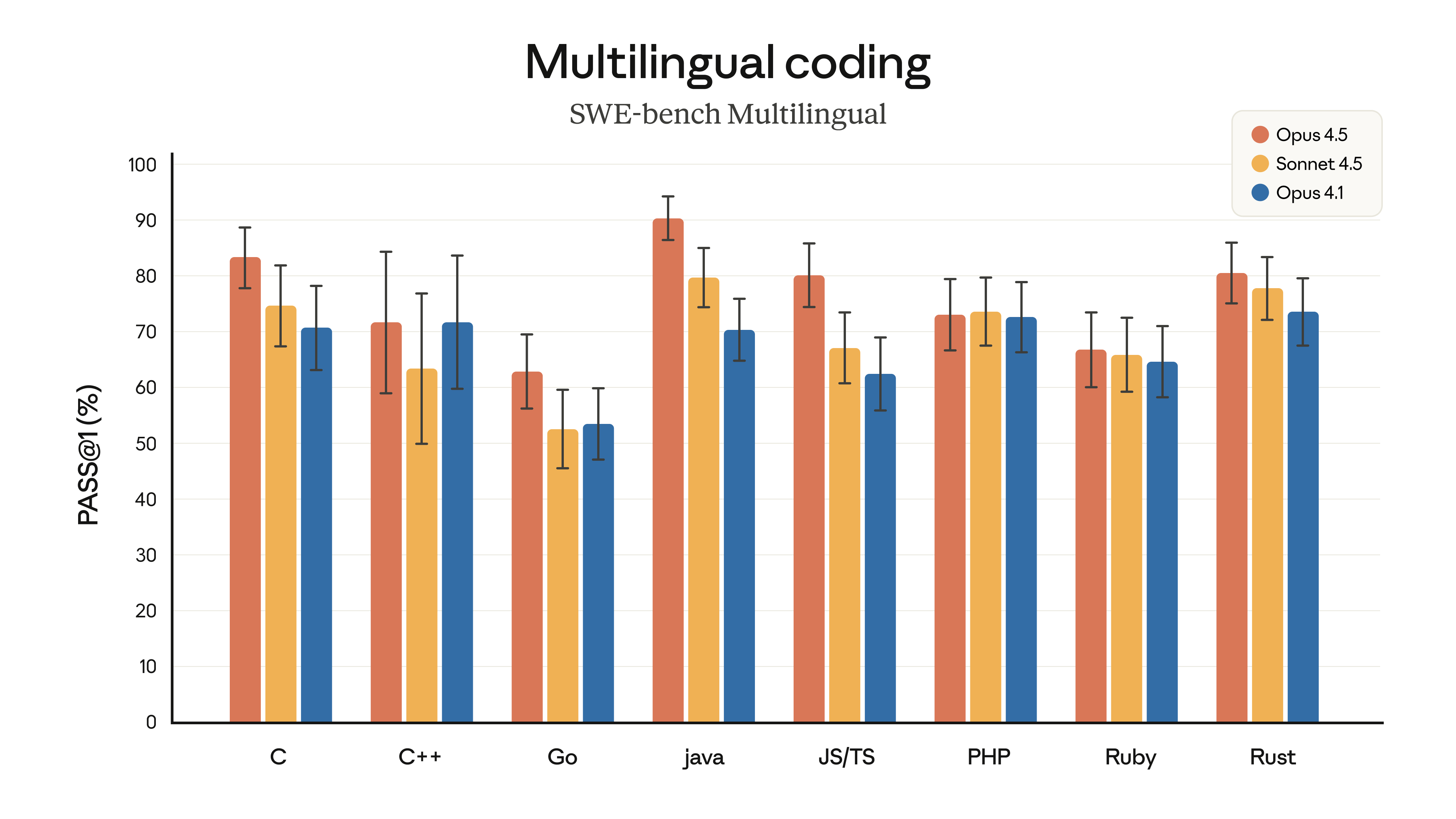
Strong performance across C, C++, Java, JavaScript/TypeScript, PHP, Ruby, and Rust demonstrates broad coding competency rather than optimization for a single language ecosystem.
Agentic Search and Deep Research
For developers building AI agents that need to browse the web, search for information, and synthesize results, Opus 4.5 shows substantial improvements:
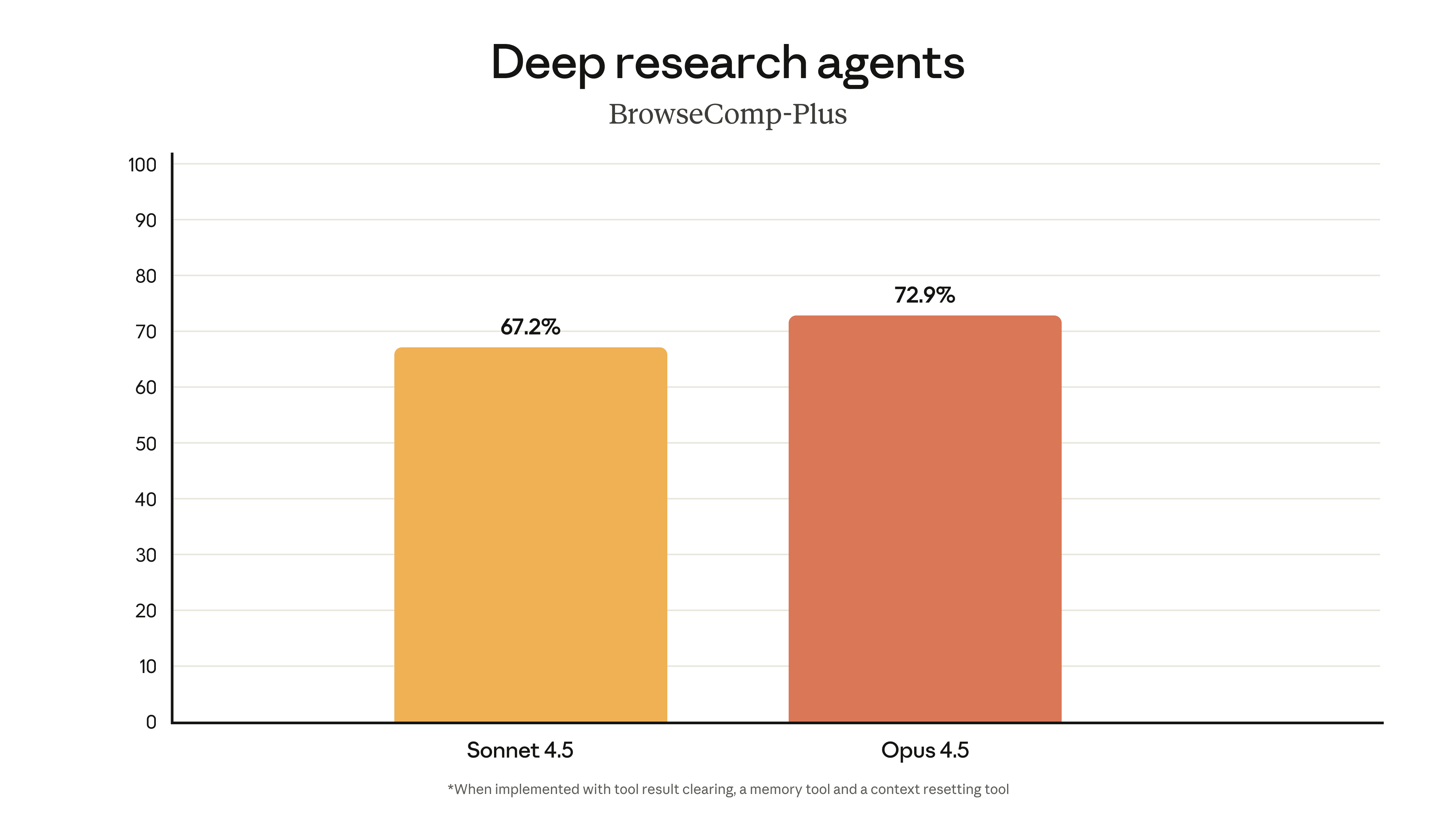
The BrowseComp-Plus benchmark specifically tests frontier agentic search capabilities—the kind of work that matters for building research assistants, competitive intelligence tools, and automated analysis systems.
Real-World Validation
Beyond benchmarks, Anthropic shared a compelling data point: Opus 4.5 scored higher than any human candidate on Anthropic's notoriously difficult internal take-home engineering exam within the 2-hour time limit.
The τ2-bench airline service scenario provides another illustration. The model identified a creative solution to a customer problem by recognizing that cabin upgrades were allowed for basic economy before flight modifications—finding a legitimate workaround the benchmark creators hadn't anticipated. This demonstrates genuine problem-solving intelligence rather than pattern matching.
Product Ecosystem Updates
Alongside the model release, Anthropic announced several product improvements:
Claude Code in Desktop App: Run multiple local and remote coding sessions in parallel directly from the desktop app. Plan Mode now generates editable markdown plans before execution.
Endless Chat: Long conversations no longer hit token limits. The system automatically summarizes context so conversations can continue indefinitely.
Claude for Chrome: Extended to all Max users for cross-tab task automation.
Claude for Excel: Expanded beta access to Max, Team, and Enterprise subscribers.
Technical Specifications
- Model ID:
claude-opus-4-5-20251101 - Context Window: 200,000 tokens
- Max Output: 64,000 tokens
- Knowledge Cutoff: March 2025
- Pricing: $5/million input, $25/million output tokens
Safety and Alignment
Anthropic describes Opus 4.5 as "the most robustly aligned model we have released to date" and likely the best-aligned frontier model available. Notably:
- Substantial progress in robustness against prompt injection attacks
- Harder to deceive than competing frontier models
- Industry-leading resistance to malicious manipulation attempts
What This Means for Developers
For those of us using AI coding assistants daily, Opus 4.5 represents a meaningful upgrade:
Cost-Performance Optimization: The effort parameter lets you match workload complexity to computational resources. Simple tasks stay cheap; complex problems get the full capability.
Agent Development: The 66.3% OSWorld score and 62.3% MCP Atlas performance make Opus 4.5 the strongest foundation for building autonomous agents that interact with computers and tools.
Enterprise Viability: The 66% price reduction makes frontier AI economically viable for more use cases. Combined with the alignment improvements, this addresses two of the biggest enterprise adoption barriers.
Competitive Coding: The 80.9% SWE-bench score means fewer iterations, better first-attempt code, and less time debugging AI-generated implementations.
The Competitive Landscape
This release puts pressure on both OpenAI and Google. A few weeks ago, Gemini 3's benchmark dominance suggested Google had pulled ahead. Opus 4.5 shifts the narrative back.
The AI model race continues to accelerate. For developers, this competition means better tools, lower prices, and faster capability improvements. The challenge is keeping up with which model works best for which use case—a problem that gets harder as models converge in capability while diverging in specific strengths.
My Take
Having used Claude models extensively for the past year, the combination of improved coding capability, better token efficiency, and dramatic cost reduction makes Opus 4.5 compelling for daily development work. The effort parameter addresses a real pain point—paying premium prices for simple queries while getting underwhelming results on complex ones.
The alignment focus is also notable. As AI models become more capable, the safety question becomes more important. Anthropic's emphasis on robustness against prompt injection is particularly relevant for anyone building production systems where adversarial inputs are possible.
For my work, Opus 4.5 is now my default model for complex coding tasks and agent development. The SWE-bench scores translate to real productivity gains when working through challenging implementation problems.
Resources:
- Claude Opus 4.5 Announcement - Official Anthropic announcement
- Claude Opus Product Page - Detailed specifications
- API Documentation - Developer integration guide
Sources:

Jason Cochran
Sofware Engineer | Cloud Consultant | Founder at Strataga
27 years of experience building enterprise software for oil & gas operators and startups. Specializing in SCADA systems, field data solutions, and AI-powered rapid development. Based in Midland, TX serving the Permian Basin.